COMMON ARCHITECTURES
Author: RAMU MEDA
Date:
Architecture is a set of structuring principles that enables a system
to be comprised of a set of simpler
systems
each with its own local
context that is independent of but not inconsistent with the context of the
larger system as a whole. [Sun Microsystems, Inc.]
Software Architecture
·
Software architecture is the structure of structures and take
away the functions that implement business requirements and what remains is
architecture.
·
Description of a structural framework to help the design of
the application.
·
The description of a development environment and
deployment configuration that supports the non-functional requirements of a software
application.
·
A software architect is most active during the early stages
of development but must participate during the entire development lifecycle of
a product.
·
Architecture is developed and described somewhere between when a vision for the product is
developed and before construction begins.
·
The software architecture must be baselined (agreed on by
all stakeholders) before construction begins because a change in the
architecture usually has vast consequences.
Architectural considerations: An
architecture can be assessed using the following qualitative measures:
·
A non-functional
requirement is one that is specified for a software system and does not pertain to
a business function to be developed in the system.
·
Non-Functional requirements are usually quality attributes
for the software system.
·
Also called service-level requirements or Quality of Service (QoS) requirements
or Non-functional requirements
·
During the inception and elaboration phases, architect works with defining the quality
of service measurement for these QoS reqs.
·
One has to make trade-offs between these requirements (For
example, if the most important service-level requirement is the performance of the system, you might sacrifice
the maintainability and extensibility of the system to ensure
that you meet the performance quality of service)
- Scalability
- Maintainability
- Reliability
- Availability
- Extensibility
- Performance
- Manageability
- Security
1. Scalability
Scalability
is the ability to economically support the required quality of service as the
load increases. There are two types of scaling:
- Sign of Scalable system: as the load
increases, the system still responds within the acceptable limits
- Capacity of a system: maximum number of processes or users a
system can handle and still maintain the quality of service
- If a system is running at
capacity and can no longer respond within an acceptable time frame, then
it has reached its maximum scalability.
- To scale a system that has met capacity,
you must add additional hardware. This additional hardware can be added
vertically or horizontally
1.1. Vertical
Scaling
- Achieved by adding capacity
(memory, CPUs, etc.) to existing servers.
- Requires few to no changes to
the architecture of a system.
- Increases: Capacity, Manageability
- Decreases: Reliability,
Availability (single failure is more likely to lead to system
failure)
- Vertical scalability is
usually cheaper than horizontal scalability.
- J2EE supports vertical scaling
because of automatic lifecycle management. Adding more capacity to a
server allows it to manage more components (EJBs, etc.).
1.2. Horizontal
Scaling
- Achieved by adding servers to
the system.
- Increases the complexity of
the system architecture.
- Increases: Reliability,
Availability, Capacity, Performance (depends on load balancing),
Flexibility
- Decreases: Manageability
(more elements in the physical architecture)
- J2EE supports horizontal
scaling because the container and server handle clustering and
load-balancing.
- Availability and reliability
are obtained through scaling. Scalability affects capacity. The more
scalable the system is the more capacity it can support. This must be
traded-off against the complexity & manageability costs.
2. Maintainability
- Maintainability is the ability
to correct flaws in the existing functionality without impacting any other
components
- cannot measure at the time of
deployment ( like extensibility )
- Features to enhance the maintainability of a system: low coupling, modularity, and documentation
- How related is this to
Flexibility? Flexibility is the ability to change the architecture to meet
new requirements in a cost-efficient manner. A flexible system should be
more maintainable in the face of changes to the environment and/or to the
application itself.
- Improves: Availability,
Reliability, Scalability
- Decreases: Performance,
Manageability
3. Reliability
- Reliability is the ability to
ensure the integrity and consistency of the application and all of its
transactions.
- You increase reliability
through the use of horizontal scalability, i.e., by adding more servers.
This only works up to a certain point, though.
- When you increase reliability
you increase availability.
- Reliability can have a
negative impact on scalability. If the system cannot maintain the
reliability as the load increases, then the system is really not scalable.
So, for a system to truly scale it must be reliable.
4. Availability
- Availability is about assuring
that services are available to the required number of users for the
required proportion of time.
- Reliability can contribute to
availability, but availability can be achieved even if components fail. By
setting up an environment of redundant components and failover, an
individual component can fail and have a negative impact on reliability,
but the service is still available due to the redundancy.
5. Extensibility
- The ability to modify or add
functionality without impacting the existing functionality.
- Features to ensure
extensibility: low
coupling, interfaces, and encapsulation
- You cannot measure
extensibility when the system is deployed, but it shows up the first time
you must extend the functionality of the system ( like maintainability )
- The key to an extensible
design is to make an effective OO design. Extensibility pays the most
towards the font end of a system.
- Some rough guidelines:
- More than 25 top-level
classes will lead to problems
- Every use case should be able
to be implemented using domain model methods
- J2EE supports extensibility
because it is component-based and allows you to separate the roles of an
app. JSPs can handle presentation. Servlets can handle routing, and EJBs
can handle business logic.
6. Performance
- Measured as response time/transaction/user or number of transactions/unit time.
- Architectural performance is
concerned with creating an architecture that forces end-to-end
performance.
- The purpose of an architecture
that ensures performance is to control expensive calls and to identify
bottlenecks.
- If you know the boundaries of
the various parts of the system, the technologies, and the capabilities of
the technologies you can do a good job of controlling performance.
- You want to minimize the
number of network calls your distributed app makes – make a few “large”
calls that get a lot of data vs. lots of calls that get small amounts of
data.
- Try to minimize
process-to-process calls because they are expensive.
- Use resource pooling to reduce
the number of expensive resources that need to be created like network
connections, database connections, etc.
7. Manageability
- Manageability refers to the
ability to manage a system to ensure the health of the system.
- A single tier or monolithic
app would be more manageable from a management perspective than a
multi-tier system but this must be weighed against the possibility of a
change rippling through a monolithic app.
- A simple architecture may not
be as flexible or available as a more complex system but the amount of
effort required to keep the system up &
functioning will be less.
- A component-based architecture
like J2EE offsets some of the manageability problems caused by a
multi-tier system.
8. Security
- Security is the ability to
ensure that the system cannot be compromised.
- Security is by far the most difficult systemic quality
to address.
- In the architecture
description of any system a description of security strategies and
implementation methods is very important
- Creating an architecture that
is separated into functional
components makes it easier to secure the system because you can build security zones around the components. If a component is
compromised, then it is easier to contain the security violation to that
component
- Security includes not only
issues of confidentiality and integrity, but also relates to Denial-of-Service (DoS) attacks that
impact availability
- Tradeoffs: personal privacy,
ease of use, and expense.
- JAAS is a Java API for authentication and
authorization that can be implemented by application server vendors, JCE for cryptography and JSSE for SSL extensions are java
technologies that support data encryption.
- A highly secure system is:
- More costly
- Harder to define and develop
- Requires
more watchdog activities
Architectural
terms: (Paul Allen Book)
- Abstraction is a symbol for something
used repeatedly in a design that hides details and is a clear
representation.
- Boundaries are the area where two
components interact.
- Brittleness is the degree to which small
changes will break large portions of the system.
- Capabilities are the non-functional,
observable system qualities including scalability, manageability,
performance, availability, reliability, and security that are defined in
terms of context.
- Friction is how much interaction
occurs between two components. Friction is measured based on how a change
in one affects both components.
- Layering is a hierarchy of separation.
- Surface Area is list of methods that are
exposed to the client.
- The key difference
between architecture and design is in the level of detail.
Architecture operates at a high level of abstraction with less detail. Design
operates at a low level of abstraction, obviously with more of an eye to
the details of implementation
- System architecture corresponds to the
concept of architecture
as a product. It is the result of a design process for a specific
system and must consider the functions of components, their interfaces,
their interactions, and constraints. This specification is the basis for
application design and implementation steps.
- Reference architecture corresponds to architecture as a style or method. It refers to a
coherent design principle used in a specific domain.
Role of an
architect: (Paul Allen Book)
- Visualizes the behavior of the system.
- Create the blueprint for the system.
- define the way in
which the elements of the system work together and
- Distinguish between functional
and nonfunctional system requirements.
- Architects are
responsible for integrating non-functional
requirements into the system.
Load Balancing Web Applications:
- Cluster: group of servers running a Web
application simultaneously, appearing to the
world as if it were a single server. Within the J2EE framework, clusters
provide an infrastructure for high availability (HA) and scalability.
- Clustering = replication + load
balancing + fail over à achieves HA +scalability+ performance
- Load balancing: the system
distributes requests to different nodes within the server cluster, with the goal of optimizing
system performance. This results in
higher availability and scalability
- Load balancers: Single points of entry into
the cluster and traffic directors to individual Web or application servers
- High Availability: can be defined as redundancy. In a highly available
system, if a single Web server fails, then another server takes over, as
transparently as possible, to process the request. A cluster only provides HA at the
application server tier. For a Web system to exhibit true HA, it must be like
Noah's ark in containing at least two of everything, including Web
servers, gateway routers, switching infrastructures, and so on.
- Scalability: application's ability to
support a growing number of users. Scalability is a measure of a range of
factors, including the number of simultaneous users a cluster can support
and the time it takes to process a request
Of
the many methods available to balance a server load, the main two are:
- DNS round robin and
- Hardware load balancers.
DNS RR Load Sharing:
- DNS is the process by which a logical name (i.e.,
www.javaworld.com) is converted to an IP address. In DNS round-robin load
balancing, a single logical name can return any IP address of the machines
in a cluster.
- Spreading incoming IP packets
among a number of DNS addresses equally.
- One host name URL but
different IP addresses.
- Simple Round Robin (but not using DNS),which is
different from DNS RR, is load balancing technique
- Advantages:
- Widely available,
easy to use, and low cost.
- A simple addition to the
name-server configuration file allows a pool of servers to be clustered
and appear to act as a single host to the clients, when in reality
requests are being alternated between all the hosts in the pool.
- Very effective for small to
medium size business or organizations. It is extremely popular among
ISPs, e-commerce sites, universities, and other cost sensitive sites.
- Disadvantages:
- No support for high availability. Inability to
handle server failures. Requests from clients will still go to this
failed server IP address when it is its turn in the round robin pool. The
result is that all of these requests will go to hosts that will not
operate correctly
- When new node is added/removed
i.e. Changes to the
cluster take time to propagate through the rest of the Internet. (DNS servers cache DNS lookups from their clients )When you
drop a node, a user may be trying to hit a non-existing server. When you
add one, that server may just be under-utilized until its IP address
propagates to all the DNS server
- Is a simple load-sharing
strategy. It does not take into account the actual load on the machines.
One or more of the hosts in the pool will tend to get more activity than
the other servers
- It is Load sharing technique rather than load
balancing. Load balancing distributes connection loads across multiple
servers, giving preference to those servers with the least amount of
congestion. In round robin's case, server distribution remains on a rigid
one IP address to one user rotating basis.
- No support for server affinity. Server affinity
is a load-balancing system's ability to manage a user's requests, either
to a specific server or any server, depending on whether session
information is maintained on the server or at an underlying, database
level.
Hardware Load Balancers:
·
The load balancer shows a single (virtual) IP address to the outside world,
which maps to the addresses of each machine in the cluster
·
When a request comes to the load balancer, it rewrites the
request's header to point to other machines in the cluster
·
Advantages
of Hardware Load Balancers:
o
Server affinity. The
hardware load balancer reads the cookies or URL readings on each request made
by the client. Based on this information, it can rewrite the header information
and send the request to the appropriate node in the cluster, where its session
is maintained.
o
High Availability through Failover.
Failover happens when one node in a cluster cannot process a request and
redirects it to another. There are two types of failover:
- Request Level Failover. When the load balancer
detects that a particular node has gone down, it redirects all
subsequent requests to that dead node to another active node in the cluster.
However, any session information on the dead node will be lost when
requests are redirected to a new node.
- Transparent Session Failover. When an
invocation fails, it's transparently routed to another node in the
cluster to complete the execution. To achieve transparent session
failover, the nodes in the cluster must collaborate among each other and
have something like a shared memory area or a common database where all
the session data is stored. Therefore, if a node in the cluster has a
problem, a session can continue in another node.
- Metrics. Used to collect metrics
data as all requests to a Web application must pass through the
load-balancing system.
·
Disadvantages
of Hardware Load Balancers:
o
Can’t
provide server affinity in HTTPS communication as the messages are SSL-encrypted,
and this prevents the load balancer from reading the session information. There
are two options to solve this problem: Web server proxies OR Hardware SSL
decoders.
o
High costs, the complexity of setting up
o
Vulnerability to a single point of failure- Since all requests pass through a single hardware load
balancer, the failure of that piece of hardware sinks the entire site
Load Balancing HTTPS Requests:
·
Web Server Proxies:
o
A Web server proxy that sits in front of a cluster of Web servers takes all requests and
decrypts them. Then it redirects them to the appropriate node, based on header
information in the header, cookies, and URL readings
o
Advantages:
§
Are that they offer a way to get server affinity for
SSL-encrypted messages, without
any extra hardware.
o
Disadvantages:
§
But extensive SSL processing puts an extra load on the proxy.
§
The hardware load balancer cannot use metrics to direct requests
§
Web server proxies need to support server affinity
·
Hardware SSL Decoder / SSL Accelerator:
o
sit in front of the hardware load balancer, allowing it to decrypt
information in cookies, headers and URLs.
o
Advantages:
§
Faster than Web server proxies
§
Off-loaded SSL processing to the SSL accelerator, which
increases scalability
§
Centralized SSL certificate management in a single box
o
Disadvantages:
§
Cost more
§
Complicated to set up and configure
Reverse Proxy load balancing:
§
Is generally used when you have servers with different
amounts of CPUs and Memory.
§
You might have some really powerful servers just to be used
for SSL sessions and others to handle static html.
§
Using this will maximize the performance of your
application
FAULT TOLERANCE:
§
Failure: discrepancy between
the desired or specified and the actual behavior of a system. Failures are external
symptoms of faults (defects).A failure is an external symptom of a fault.
§
Fault: defect with the
potential to cause a failure. While it has this potential, it may never
actually do so. A failure is a guarantee that a fault has occurred.3 types of faults: server process fault, server fault,
network fault
§
Fault
tolerance:
the ability to prevent failures even when some of the system components have
faults.
§
The key to achieving fault tolerance is redundancy. Redundancy requires replication
§
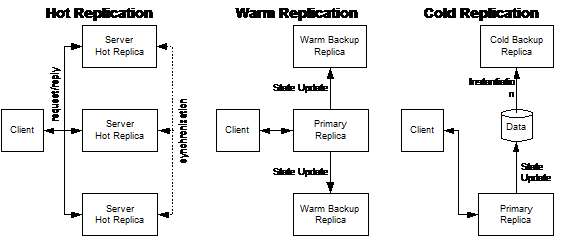
Hot
backup / Active Replication: Extra, live copies (replicas) of an object are serving
client requests and synchronize continuously with the primary object. If the
primary object fails, one of the copies takes over. Every replica handles
requests and replies. Interceptor has to block extra calls to third objects and
extra responses
§
Warm
backup / Passive Replication: Backup copies of an object run, but don’t serve clients. Synchronization
happens at certain, regular intervals. One primary replica handles requests and
synchronizes state with secondary replicas. Requests are also logged. For
fail-over, a secondary replica becomes primary and processes all requests after
the last synchronization point
§
Cold
backup:
The primary object synchronizes with stable storage in certain intervals. In
the case of a failure, a new object is instantiated and reads the storage for
set-up.
§
Hot
backup or active replication is for Load balancing also. But the Warm backup/
passive replication and cold backup are not for load balancing, but only for
fault tolerance.
§
Fault
handling
includes service
replication, fault detection, fault recovery, and fault notification.
§
Fault detection is often done by using heartbeats (server
sends periodical signal to monitor) or polling (monitor checks server once in a
while).
§
Fault handling in CORBA involves Replica Managers and
Replica Service Agents.
Comparison of J2EE architecture with
Microsoft DNA Architecture:
- Component types supported. Windows DNA has
no support for data components, whereas J2EE platform-based products
support both types of components (data components and business
components).
- State management. Windows DNA has very poor
support for a stateful business process component, and does not provide
state management services. J2EE platform-based products support stateful
business processes today.
- Database caching. A robust data caching system
enhances the scalability of a commerce system significantly. The Windows
DNA architecture provides automatic result set caching for applications.
Unfortunately, Windows DNA does not include support for data object
caching, nor for distributed shared data object caching. This
significantly impairs the scalability of a Windows DNA deployment compared
to a J2EE platform-based deployment.
- Declarative (automated) persistence. A declarative
persistence model enables developers to persist enterprise data without
writing code, such as Java Database Connectivity (JDBC) code. This reduces
coding time significantly, and allows one to author database independent code.
Windows DNA does not support declarative persistence as it doesn’t support
data components. By way of comparison, several vendors implementing the
J2EE platform support complex automated persistence today.
- Scalability through load-balancing. For a scalable multi-tier
deployment, a corporation must be able to add middle tier machines as
necessary to handle high-volume transactional load. This requires logic to
automatically load-balance across middle tier components. Windows DNA
contains load-balancing technology to spread IP traffic among Web servers,
which is called Network Load-Balancing. This technology is effective at
balancing incoming requests to Web server machines. Microsoft does not
currently offer load-balancing technology that directs requests from the
presentation tier to the business tier
|
Supply Chain
Collaboration: Spoke, Exchange, or Hub : B2B
- Basis for
Supply-chain collaboration à CPFR: Collaborative
Planning, Forecasting and Replenishment
Spoke
- Working with
trading partners over the Internet by sub-scribing to a large partner’s extranet
hub.
- These ex-tranets
typically provide online access through a web browser to reports of
supply chain activity, as well as key performance measures
- two sets of
benefits:
- Speed and ease of getting
access.
- Richness of the information that is
available. Trading partners only need a PC and Internet access to take
advantage of the extranet. Typically they do not need to purchase,
install and configure any software, or translate data from some
machine-readable format to review it.
- The problems with
using partners’ extranets are also twofold:
- Users only get to see the data one partner at a
time. Assembling the “big picture” of a company’s supply chain
performance and customer demand from multiple trading partner extranet
reports is next to impossible.
- Making sense of data that is
represented in terms of a partner’s geographies, channels and product
categories is difficult. A retailer typically shows its data by
department, while a manufacturer needs data by brand. Retailer
departmental data may not map well to a manufacturer’s brands.
Differences in multiple partners’ views further complicate the problem.
- Being a spoke on
a trading partner extranet hub is an excellent way to ex-periment, but a
difficult way to move supply chain collaboration into production.
- Relationships can only be managed
one-on-one, and
- Data is difficult to translate to
local company needs.
- The approach is
most appropriate if a company is small, or limited in IT capabilities,
and does most of its business with a single large customer or supplier.
Exchange
- Demand from several
trading partners can be integrated and represented in each company’s own
category, geography, and channel views.
- The exchange
handles IT
implementation issues, so local company IT investment is minimal.
- Each partner simply
supplies core supply
chain data to the exchange; beyond that, all access is by users through
their web browsers.
- three limitations
of using a B2B exchange to implement supply chain collaboration:
- An exchange may represent a large number
of trading partners, but it is unlikely to represent all of a company’s
trading partners. Strategic
partners may be missing.
- An exchange provides only a standard offering – some
manufacturers and retailers may wish to collaborate with a different
workflow process or data conventions.
- There are technical limits to the amount of
data that a B2B exchange can host. If a large retailer wishes
to provide supply chain collaboration at a store level on a daily basis,
it is currently not feasible to replicate the required data to a B2B
exchange.
Hub ~~Trading Partner’s Extranet Hub
- Building and
managing a trading partner extranet can be a major undertaking.
- For medium-to-large companies who need to gain
the maximum competitive advantage it is probably a necessity.
- Only on its own hub
can a company
aggregate the demand from its entire network, includ-ing strategic
partners, exchanges, and internal relationships (for vertically integrated
companies).
- For retailers who wish to drive collaboration
down to the detailed level – daily, store-level data, and 52-week or
longer forecasts that are updated frequently – im-plementing CPFR directly
on their own enterprise data warehouse is the only practical solution, at
least today
What Is The
Difference Between B2B and B2C?
B2B
- Concerns itself
primarily with supply
chain management.
- These are portals
that allow businesses
to deal directly with their suppliers and distributors online
- Wholesalers, distributors and
manufacturers fall in this category
- B2B sites normally
handle a lot more than just sales of products; they are a portal to conduct business transactions.
B2C
- B2C concerns itself
with selling to the
end user
- They are actually internet based. That is to say
they exist primarily on the internet. Offices and warehousing are borne
from necessity of their internet success.
- B2C websites are
intermediary portals to
link customers to suppliers
- All of these
businesses exist primarily on the internet. They are what is known as e-businesses
- All of them can be
classified under one general heading, market places.
- A B2B site deals
primarily with other businesses, not the general public, a B2C site sells
directly to the end user
One Tier
Architecture:
- Think of an application that runs on your PC: Everything you
need to run the application (data storage, business logic, user interface,
and so forth) is wrapped up together
- Monolithic,
“all-in-one” model – e.g. clients are “dumb” terminals connected directly
to the mainframe.
- is a simple design that's easy to
distribute, it does not
scale well
- does not adequately
address the needs of a web-based application
- Scalability à Poor.
Vertical scalability only;
expansion capabilities are physically limited (e.g. free CPU slots,
terminal ports)
- Security à Good à as the connectivity is physically limited
- Extensibility à Poor à component reuse
difficult due to tight-couplingà as any change affects the
entire system
- Availability à Poor à Single point of failure
- Maintainability à Poor à any change affects
the entire system
- Performance à Mixed à Pros: no remote process communication; àCons: a runaway process could
affect others
- Manageability àgood as the all are
at one place.
- Reliability à Mixed à Risk of failure
Two Tier
Architecture / Client – Server Model:
- Typically composed
of multiple clients and a single server; the clients connect to the server
over a network
- Fat Client e.g. implements the GUI,
retrieves data from the server(s), and performs business logic based on
the data. E.g.: use of Java-applets
- Server is typically
a database. Provides a shared
data-store for the client.
- The server doesn’t
typically implement business logic. Later revisions to the model implement
some of the business logic on the server as stored procedures (a.k.a. fat servers).
- Fat Servers: the client is
used only to perform the display portion of the presentation component,
and the server performs most of the presentation logic and all of the
business and data access logic. e.g. in typical web-applications where the
browser has to cope with HTML
- Problems with the
2-tier model are :
- The business logic
may be complex and computationally expensive. Consequently, the client may require powerful
hardware
- client components
are tightly coupled, not modular –
e.g. a change to the GUI means shipping the whole application to every
client
- Data retrieval - each client has to make a direct
connection to each server it needs data from. Also, the results transferred
may be large and transferred using an inefficient (and perhaps
proprietary)protocol
- Fat servers use stored
procedures which are not
very portable.
- Security à Poor à Client: difficult
to enforce the security policy (fat clients are distributed all over the
place; could be used/accessed by anyone); available options are
SSL/VPN/user authentication (too coarse); Server: has to be exposed to the outside world
for client access so vulnerable to attack.
- Extensibility à Poor à Client: client
tightly coupled to the business logic (although code may be reused for
clients that support the language the code is written in, there would be
multiple deployments); Server: if using a fat server, stored procedures
have to be provided for each DB used.
- Availability à Poor àsingle point of
failure (usually a single database)
- Reliability à Mixed à availability and performance
issues
- Maintainability à Poor à Client: updates
have to be applied to all clients in turn; Server: ok - everything in
one place; simple to troubleshoot
- Performance à Poor à Client: result may be large;
result data transfer protocol may be inefficient; client may be
underpowered (local processing may be intensive); Server: ok – e.g. DB caching
- Scalability à Poor à Client: each client requires
a separate DB connection; Server: server can be scaled vertically; some
horizontal scaling is possible but potentially requires client intelligence
- Manageability à in between 1-tier
and n-tier
3 - Tier Architecture:
- In the typical
example of this model, the web browser acts as the client, an application
handles the business logic, and a separate tier handles database
functions.
- 3-tier architecture
is the most common approach used for web applications today.
- Although the 3-tier
approach increases scalability and introduces a separation of business
logic from the display and database layers, it does not truly separate the
application into specialized, functional layers. For prototype or simple
web applications, 3-tier architecture may be sufficient. However, with
complex demands placed on web applications, a 3-tiered approach falls
short in several key areas, including flexibility and scalability. These
shortcomings occur mainly because the business logic tier is still too
broad- it has too many functions grouped into one tier that could be
separated out into a finer grained model.
N Tier Architecture:
- The single most
important benefit of an n-tiered architecture, compared to a 3-tier
approach, is breaking up the business logic from the application-server
level into a more fine-grained model
- The separation of
concerns, packaging, and service distribution helps immensely in maintainability, scalability
and flexibility of deployment configurations
- Scalability à Good à Good modular which
supports vertical/horizontal scaling; multiple instances; demand-based
pooling
- Security à Good à Pros: security can be applied
to each tier and targeted where required; à Cons: complex architecture so
something could be missed; more to secure so could be expensive
- Extensibility à Good à Good modular in
nature so components can be added/replaced as required; business logic is
centralized on the app servers
- Reliability à Good à as the availability and performance are good
- Availability à Good à because of
clustering à Pros: multiple instances (no
single point of failure); Cons: expensive
- Maintainability à good à Pros: multiple instances
(facilitates day-to-day maintenance); centralized business logic so easy
to update; Cons: complex; distributed in nature; difficult to troubleshoot;
requires ASAs (app server admins), DBAs
- Manageability à Mixed à compenent architecture
lessens the burden
- Performance à Good à Pros: load
balanced over multiple instances; instance and DB pooling; caching;
specific modules can be tuned in isolation; à Cons: process communication
overhead (e.g. remote method invocation creates an overhead which affects
performance)
N Tier J2EE
Architecture:
- Web Client Tier:
- The Web Client
Tier is visible to the end user.
- This tier consists
of the HTML that is generated from either Java Server Pages (JSP) or
parsed XML documents, and is viewed using a web-browser such as Internet
Explorer or Netscape Navigator. The web browser will format the HTML
using Cascading Style Sheets (CSS).
- Tier Constraint:
Components in this tier must only display business data and capture user gestures
for change requests.
- This tier
participates in the implementation of the View and Control of MVC.
- Technologies:
- Java Based
Technologies: Applets, Applications.
- Related
Technologies: HTML, HTML Forms, JavaScript, Style Sheets, SSL
- Non-Java
Technologies: MS Active Technologies such as ActiveX and OLE, VB Script,
Jscript.
- Protocol: HTTP,
HTTPS.
- Presentation Tier
- Responsible for
the generation of the views (i.e. the HTML pages that are delivered to
the browser).
- The components in
this tier use JSP technology to access the business tier to query for
data and to communicate the changes to it as requested by the user.
- Tier Constraints:
Components and objects in this tier must interpret business data and
generate documents that can be viewed by web browsers. They must also be
capable of receiving change requests from the web client tier and passing
it on to the Business Tier.
- This tier
participates in the implementation of the View and Control of MVC.
- Technologies:
- Java Based
Technologies: JSP, Servlets.
- Related
Technologies: Web Services, SOAP.
- Non-Java
Technologies: MS Active Server
Pages.
- Protocol: JRMP,
IIOP, RMI-IIOP.
- Business Tier
- Business logic and
rules are implemented in this tier.
- The components in
this tier model business objects and concepts of the application.
- The design provides
a layer of abstraction giving us implementation transparency to the data
store and mechanisms.
- These components
are the interfaces to data and provide essential services such as
transaction monitoring, data integrity availability etc.
- Tier Constraints:
- The components in
this tier must contain business logic, rules and represent business
data.
- The container of
the components of this tier must provide transaction management,
component lifecycle management, enable load handling and fault tolerance
and other services as specified in the product requirements.
- This tier
participates in the Control and Model of MVC.
- Technologies:
- Java Based
Technologies: EJB (the mainstay of J2EE), JTA, JTS
- Related
Technologies: JNDI, CORBA, RMI.
- Non-Java
Technologies: COM, DCOM, COM+.
- Integration Tier
- This contains
objects, components and services that provide data connectivity.
- The APIs used in
this tier hides the heterogeneous nature of resources that is available
and necessary for business operations. For example data from an oracle
database or a bar code scanner can be treated pretty much the same way by
the objects in business tier thanks to this tier.
- Tier Constraints:
- Components in
this tier must enable the communication of the business tier with the
resource tier.
- This
communication must be location transparent and homogenous to the
business tier.
- This tier
participates in the Model of MVC.
- Technologies:
- Java Based
Technologies: JDBC, JCA, JMS, JDO
- Related
Technologies: Messaging products like MQSeries, SonicMQ
- Non-Java
Technologies: ODBC, OLEDB,
- Resources Tier / Data Tier
/Persistence Tier
- This tier can also
be called data tier, persistence tier etc. This tier is where data for
the business application is stored. Other resources such as real-time
data collects like barcode scanners can also belong to this tier.
- Tier Constraints:
The contents of this tier must provide persistence of business objects
represented in the business tier.
- This tier
participates in the Model of MVC.
- Technologies:
- Related Technologies:
RDBMS, Mainframes, CICS, ERP Systems like SAP, barcode scanners